We're starting to think more seriously about issues such as deposition identifiers for ChEMBL, since we are getting significant interest in direct depositions, often as a sort of supplementary material associated with a publication. It is great that we're seeing this interest from two communities, close to our hearts and interests - 1) large pharma actually walking-the-walk on data sharing, as opposed to the talking-the-talk with little follow through (We'll be able to make an announcement on this fairly soon). and 2) the neglected disease community (again an exciting announcement soon, I feel like such a tease, sorry).
Some of the other resources at the EBI are starting to assign DOIs for these sort of citable depositions (e.g.Intact), so your thoughts on the positives and negatives of this approach would be appreciated.
This leads on to the broader issue of data provenance - I would like to think that the data in ChEMBL has reasonable provenance - there are pointers to the original publications, depositions, database identifiers are stable (so if we fix a target or compound structure, we assign a new identifier - others not doing this is a big pain for our integration, and this is one of the reasons we built UniChem). The data is also versioned and there is a proper defined and stable license for the data (CC-BY-SA 3.0).
One of the issue though we have with support is with derivative works - lots of resources have integrated ChEMBL now - this is fabulous for us - sometimes as a one-time load for an analysis, and sometimes regularly updated. However, some resources are woefully out of date in keeping their copy of ChEMBL up to date. Imagine, those poor users losing out on all the fixing and curation the annotation pixies here in Hinxton have been up to. Most sites don't even maintain an inventory of their feeder sources, let alone versioning, release info and dates.
Is there any best practice in this area? We could publicise loads of ChEMBL here on the ChEMBL-og for example?
Anyway, these sort of data provenance issues are one of the areas being studied in the fabulous IMI OpenPHACTS project.
As always, comments or an email would be most welcome (I must admit, I get by far most feedback by mail, and feel a little bit guilty in posting this publicly - so be brave, post in the comments!).
On June 27th, the FDA approved Lorcaserin hydrochloride (Tradename: BelviqTM; Research Code: APD-356), a selective serotonin 2C receptor (5HT2c) agonist, for chronic weight management in adults with an initial body mass index (BMI) equal or higher than 30 kg/m2 (obese), or equal or higher than 27 kg/m2 (overweight) and with one weight-associated comorbid condition (e.g. hypertension, dyslipidemia, type 2 diabetes).
Lorcaserin is believed to decrease food consumption and promote satiety by selectively activating 5-HT2C receptors on anorexigenic pro-opiomelanocortin neurones in the hypothalamus. The exact mechanism of action is not fully established. However, at therapeutic concentrations, lorcaserin is selective for 5-HT2C receptors as compared to 5-HT2B receptors, making it less prone to cardiovascular side-effects, associated with previous 5-HT2C weight management drugs. It is the first anti-obesity drug to be approved after the withdraw of Dexfenfluramine in 1997. Given the safety issues of previous drugs, the development has focussed on safety, and with the data in hand, lorcaserin has been approved without a boxed warning.
The 5-HT2C receptor (Uniprot: P28335, ChEMBL: CHEMBL225) belongs to the G-protein coupled receptor (GPCR) type 1 family, and binds the endogenous neurotransmitter serotonin. Its activation inhibits dopamine and norepinephrine release.
Lorcaserin (IUPAC: (5R)-7-chloro-5-methyl-2,3,4,5-tetrahydro-1H-3-benzazepine; Canonical smiles: C[C@H]1CNCCc2ccc(Cl)cc12; PubChem: 11658860; Chemspider: 9833595; ChEMBLID: CHEMBL360328; Standard InChI Key: XTTZERNUQAFMOF-QMMMGPOBSA-N) is a benzazepine with a single chiral center, with a molecular weight of 195.7 Da, 1 hydrogen bond acceptor, 1 hydrogen bond donor, and has an ALogP of 2.75. The compound is therefore fully rule-of-five compliant.
Lorcaserin is available as film-coated oral tablets of 10 mg, and the recommend daily dose is 20mg. The plasma half-life of lorcaserin (t1/2) is approximately 11 hr, and is moderately bound (~70%) to human plasma proteins. The absolute bioavailability of lorcaserin has not been reported.
Lorcaserin is extensively metabolised in the liver by multiple enzymatic pathways, however it inhibits CYP2D6, and therefore an increase in exposure of CYP 2D6 substrates may occur. The two major metabolites are lorcaserin sulfamate, and N-carbamoyl glucuronide lorcaserin.
As a serotonergic drug, patients should be monitored for the emergence of serotonin syndrome. For the full list of adverse reactions and drug-drug interactions please refer to the full prescribing information.
The license holder for BelviqTM is Arena Pharmaceuticals, and the full prescribing information can be found here.
So some very sad news yesterday - the announcement of the closure of the Nutley R&D facilities of Roche. Families disrupted, kids moved to new schools, partners careers affected, and then inevitable greater competition for the few remaining jobs and downward pressure on salary and benefits. It's a tough time to be a drug discoverer wanting to work in industry. Quite striking to me in this is the geographical focussing of the drug discovery industry in three places, Cambridge MA, Cambridge Cambs (or 'Cambridge Classic' as I call it) and Basel (you could also add a fourth, South San Francisco to this list, maybe). You can understand why this happens, the companies want access to a 'liquid' talent pool, and employees want 'robustness' to future layoffs, and this leads to focussing of 'resources' in a few geographical locations.
Would be interesting to pull together the data for the last 40 years on R&D site locations and staff sizes, and then plot them on one an interactive maps - showing first growth, and then retrenchment. Load me up with some armodafinil, and I'll have a go.
This is a last call for people who would like to sign up for the "Schema & SQL Querying" webinar that will be hosted this Wednesday 27th June at 3.30pm (BST). It will be a 45 minute webinar that will take you through the ChEMBL schema and also how to use SQL queries to extract data from the database. Remember to register your interest in our webinars on theDoodle Poll. Make sure that you leave your **email address** as well as your name so that we can send the connection details to you. Any problems, please contact chembl-help@ebi.ac.uk.
once over the initial shock, I thought what could she be talking about - did she know about the short-cut I use to get to the river to watch the trout?, or that I sometimes asked people in front of me in the queue for the coffee machine to get me a coffee to save my time at the inconsiderate expense of those in front of me? No, it was because I was involved in "Open Access" - lucky then she didn't know then that I was actually really working on a more extreme version - the more fundamentalist version that is the destroyer of capitalism - Open Data! ;)
I said,
"Princess, it's not that bad; honest; Daddy isn't a bad man",
she laughed at my distressed response, and then said
The Daily Mail is the most widely read UK newspaper, it also is a well known source of shockers about health threats and benefits from just about household object or food, but the fact is it's read by about 4,400,000 million Britons every day.
Here is the introductory paragraph of the article (used under 'fair use').
Up to £1billion of income and thousands of jobs could be placed at risk as a result of a move by Downing Street to allow Google and other digital search engines ‘open access’ to the nation’s best academic and scientific research.
So a lot of jobs are going to go in the UK and we're going to lose 'income' (what is that tax income? sales revenue?, etc). I don't also quite understand the distinction between academic and scientific - I thought the mandatory open access proposals were connected solely with publicly funded research, and don't, and shouldn't, extend to privately sponsored research - if that is behind the distinction. Downing Street and Google are also semi-structured concepts plucked from the ether to build a web of plausibility for what follows - ultimately feeding xenophobia and protectionism.
Here is some more from the article,
But UK businesses fear that the proposals will destroy Britain’s highly-regarded academic publishing industry that modifies raw research, publishes it in the form of academic magazines, journals and books and exports it to the rest of the world.
Use of the word 'exports' is also contrived, most would agree, but which UK businesses will suffer? . Well, it turns out publishing businesses that make significant profits from the current system, they are becoming concerned may be threatened by this proposed change to UK research publication.
You're all intelligent and well informed, so I don't need to comment any more, but just read it, go on, read it!
One leading publishing group said the move to provide all of Britain’s academic output online for nothing could destroy a £1 billion industry that employs 10,000 people here and in its overseas operations.
Much of the scientific work from the nation’s leading research universities is passed on to the academic publishing industry where it is subjected to so-called ‘peer review’, or examination by experts, before it is published in journals and books that are also available online.
The material is a valuable source of income to UK publishing houses such as Reed Elsevier, one of Britain’s leading publishers with a market value of £6billion, as well as the hugely-respected Oxford University and Cambridge University Presses.
and also
In reality academic publishers and researchers fear that scientific and other academic studies, paid for by the taxpayer, will be made freely available to researchers in China and elsewhere in the Far East.
Most rational people would say good to this, that's the way global science is meant to work. Also who were the researchers that would have agreed with this nonsense? I always thought of Reed-Elsevier as a globally operating Anglo-Dutch company, as opposed to deeply rooted and primarily operating within the United Kingdom, which is the impression most readers would be left with.
This is the funniest bit though...
Publishers are concerned that if an open access policy is adopted then some of the biggest scientific companies, such as GlaxoSmithKline, might move research work from British labs to those overseas where it will able to protect itself from open access.
Not attributed to GSK themselves of course but a sort of 'Munchausen's by proxy' worry on behalf of others. The concept of moving overseas to protect your business from open access is just so funny -especially given GSKs activities in pre-competitive activities, collaboration, and Open Data release.
There's also stuff linking the proposal to make more research available to people to internet piracy, etc.
Seriously though, the fact that this sort of nonsense is read by a very large number of people, and aimed directly at influencing public opinion is, to me, scary. The implicit threats in the article and linkage to economic stability and national competitiveness is, arguably irresponsible.
What have I learnt from this? - well the debate and argument isn't to be held amongst ourselves, it's with the public, the broad base of funders (via their tax contributions, bequests and charitable donations) of our work. We should make them proud of the way we spend their money, we should be accountable for this, and our output should be available for all of them - not just in our own country, but throughout the world.
Imagine the pride for a researcher mother or father when they get a random call from their kids, saying
"Hey, I'm so proud that you work in Open Access, and all my friends think you're way cool"
The Teach-Discover-Treat (TDT) initiative
was launched at the ACS meeting in San Diego under the umbrella of the Computers
in Chemistry Division. The slides that describe the initiative are available on
the website www.teach-discover-treat.org
TDT aims to address outstanding gaps in
drug discovery education and treatments for neglected diseases. A competition
was launched that solicits submissions of computational models and tutorials
for drug discovery for neglected diseases. All tools used for the computational
workflows must be freely available (open source, free web servers, free
download of executables) to enable global collaboration and innovation.
There are 4 categories in the competition,
and 4 awards!Three of the categories
are focused on specific neglected diseases for which datasets have been
provided. Specific requirements have been formulated for the workflows that are
to be the submissions for the competition in these three categories. The
requirements are outlined in the readme files that are part of the data
download packages. Additional background information is available in the slides
from the kick-off symposium, which can be found on the website. Real-life
impact on these three challenges will be realized through experimental
follow-up on the winning submissions (compound acquisition, synthesis, and
biochemical testing through various academic partnerships). A fourth "open
innovation" category seeks innovative drug discovery workflows that are
either exemplified on a neglected disease project or adaptable to a neglected
disease application.
Bissan and I just had a really good breakfast discussion on drugs, and it prompted me to do a picture for the blog. There'll be some more, depending on collecting glasses from the opticians, getting some ivermectin for the tick infections that have appeared on Vini and Bruce the bearded dragons (named after two of the major protagonists of the fantastic and situationist durutti column), the length of the queue of cars at the municipal tip in Sutton, and other weekend domestic stuff.
Carbon and Oxygen are two essential life elements, and really important in drug structures - in fact, most drugs are 'organic' chemicals - those based on primarily on carbon chemistry. Carbon and oxygen can be combined in chemical reactions in various ways to give a number of compounds - they are all oxides of carbon. These are...
Carbon dioxide - CO2 - that well known environmental villain (and also life sustaining chemical)
Carbon monoxide - CO - that well known poison (and also endogenous signalling molecule)
Carbon suboxide - C3O2 - that not so well known oxide of carbon (this one has few virtues) This is one of my interview questions to probe people's chemistry knowledge (keep this important fact a secret though).
As an interesting aside these are all linear molecules.
Imagine the atom ratios of these compounds plotted on a line, between a carbon ratio 1.0 (the element carbon, which occurs in a variety of expensive/worthless allotropes) and 0.0 (which would be the element oxygen - which physically, under normal conditions occurs as that life giving molecule dioxygen (which can also be poisonous), and ozone (again that life giving/taking molecule)). So for the carbon oxides, CO is at coordinate 0.5, CO2 at 0.333, etc. This is what it looks like.....
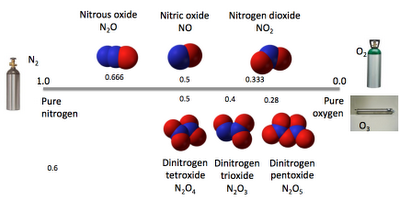
Update - here's the same but for combinations of oxygen and nitrogen.
Of course, things become more interesting when you mix in more elements...... What I am discovering though is that triangular graphs are more complicated than I remember from when I was 12 years old.
So, congratulations are in the air again - this time to Janet Thornton (although the wikipedia page is now out of date), Director of the EMBL-EBI. Janet has just been awarded the British honour of Dame Commander of the Most Excellent Order of the British Empire (DBE) in the 2012 Queen's Birthday Honours list. This is absolutely fantastic news, and well done from all in the ChEMBL group. Many of you will already know Janet's fantastic track record of innovation in the study of protein structure, enzyme function, and more recently in some of the molecular processes of ageing - but Janet has also done great things in championing the sharing of biological data, and in encouraging sharing and collaboration on a global and international scale, for example via the establishment of the ELIXIR infrastructure.
It's great to see her achievements and service recognised more broadly in society through this titular honour.
Update: someone has updated the wikipedia page. Citizen curation in action!






 The Teach-Discover-Treat (TDT) initiative was launched at the ACS meeting in San Diego under the umbrella of the Computers in Chemistry Division. The slides that describe the initiative are available on the website www.teach-discover-treat.orgTDT aims to address outstanding gaps in drug discovery education and treatments for neglected diseases. A competition was launched that solicits submissions of computational models and tutorials for drug discovery for neglected diseases. All tools used for the computational workflows must be freely available (open source, free web servers, free download of executables) to enable global collaboration and innovation.There are 4 categories in the competition, and 4 awards! Three of the categories are focused on specific neglected diseases for which datasets have been provided. Specific requirements have been formulated for the workflows that are to be the submissions for the competition in these three categories. The requirements are outlined in the readme files that are part of the data download packages. Additional background information is available in the slides from the kick-off symposium, which can be found on the website. Real-life impact on these three challenges will be realized through experimental follow-up on the winning submissions (compound acquisition, synthesis, and biochemical testing through various academic partnerships). A fourth "open innovation" category seeks innovative drug discovery workflows that are either exemplified on a neglected disease project or adaptable to a neglected disease application.The datasets for the competition are available here: http://www.teach-discover-treat.org/downloadsVisit the website www.teach-discover-treat.org for comprehensive information and note that the competition closes on September 5, 2012.
The Teach-Discover-Treat (TDT) initiative was launched at the ACS meeting in San Diego under the umbrella of the Computers in Chemistry Division. The slides that describe the initiative are available on the website www.teach-discover-treat.orgTDT aims to address outstanding gaps in drug discovery education and treatments for neglected diseases. A competition was launched that solicits submissions of computational models and tutorials for drug discovery for neglected diseases. All tools used for the computational workflows must be freely available (open source, free web servers, free download of executables) to enable global collaboration and innovation.There are 4 categories in the competition, and 4 awards! Three of the categories are focused on specific neglected diseases for which datasets have been provided. Specific requirements have been formulated for the workflows that are to be the submissions for the competition in these three categories. The requirements are outlined in the readme files that are part of the data download packages. Additional background information is available in the slides from the kick-off symposium, which can be found on the website. Real-life impact on these three challenges will be realized through experimental follow-up on the winning submissions (compound acquisition, synthesis, and biochemical testing through various academic partnerships). A fourth "open innovation" category seeks innovative drug discovery workflows that are either exemplified on a neglected disease project or adaptable to a neglected disease application.The datasets for the competition are available here: http://www.teach-discover-treat.org/downloadsVisit the website www.teach-discover-treat.org for comprehensive information and note that the competition closes on September 5, 2012.