SureChEMBL - Chemical Structure Information in Patents
Today we have announced that we are taking over the running of the SureChem system from Digital Science. We have renamed this SureChEMBL to reflect the history and provenance of the technology and engineering, but also to align it with it's new home and future, we like the name, and hope you do. We are delighted that this has happened - Nicko and the team at Digital Science have been great, and the more we have dug in to how it works, the more we have appreciated the design and vision that they had.
If there is one consistent piece of feedback we get about ChEMBL it is in encouraging us to add patent data to what we do. So now we have, but because the data from patents is different in detail from that reported in the published literature, we will keep the databases separate, but closely integrated.
For those of you that are already SureChem users you will be familiar with the functionality and how it works; but for those that weren't SureChEMBL takes feeds of full text patents, identifies chemical objects from either the in-line text or from images and adds 2-D chemical structures. This is then loaded into a database and is searchable by chemical structure, so you can do substructure, similarity searching and so forth - all the good things you'd expect from a chemical database. This chemical search functionality is unavailable from the public, published patent documents, and is really essential for anyone seriously using the patent literature. Oh, and the system does this live, so as patents are published, they are processed and added to the system - the delay between publication and structures being available in SureChEMBL is about a day when converted from text, and a few days when converted from image sources.
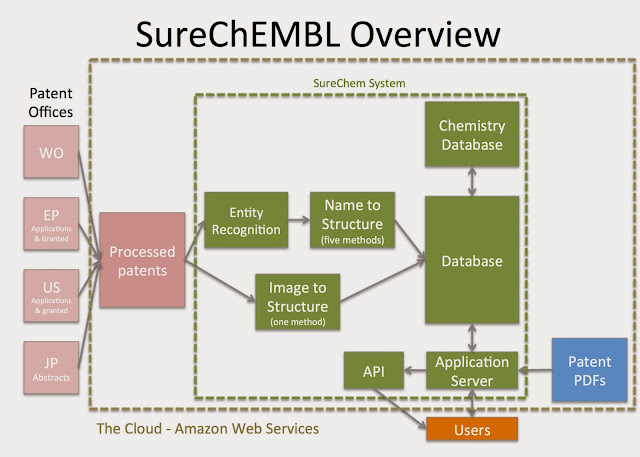
SureChEMBL is hosted on the cloud - it's quite a complicated AWS solution, and it will take a few months for us to assume complete control of all the various parts, and, importantly keep things running smoothly behind the scenes, so the continuous access to fresh patent data is maintained.
SureChEMBL uses a number of third part software products in its operation, and arranging the licenses and permissions has been complex, and is still ongoing. The 3rd party software and data feeds used in SureChEMBL include:
Name to structure: ChemAxon, ACD/Labs, Perkin Elmer, OpenEye, OPSIN, NextMove
Chemical cartridge: ChemAxon
Image to structure: Key
Module
Patent data: FairView (IFI
Claims) – processed patents, TwinDolphin –
patent PDFs
These guys have all been a pleasure to work with so far, and SureChEMBL is a great showcase of their respective technologies and data:
We will host the system at the primary urls http://www.ebi.ac.uk/surechembl and also at http://www.surechembl.org - at the moment , these redirect to www.surechem.org, but as we switch things over they will point to servers provisioned by our team, so please start using these new urls for future access, although the original urls will continue to work into the future.
One of the more complicated things to transfer is the user accounts system - we can't simply transfer them over - and so have a plan to mail batches of users once a new sign-on system is in place in order to invite them to sign up to the new user account system. If you are not currently a registered user, please sign up with the current system, and we'll invite you to transfer over to our sign-on system once things are ready.
The EMBL-EBI has a broad range of life-science chemistry resources, and we integrate across chemistry related content using a chemical structure integration system call UniChem. In overview the EMBL-EBI chemistry resources include the following.

The future? - well the future is exciting, and we have lots of ideas to actively develop the SureChEMBL system. To be clear though, doing this will rely on us getting funding, and we're working hard on this. Some of the ideas we have for SureChEMBL include:
- Put SureChEMBL chemical content into UniChem
- Add sequence searching
- Add disease term, animal model, etc. indexing
- Development of community KNIME nodes
- Add links to/from Europe PMC
- Ligand Ensemble-based mapping of ChEMBL literature to patents
- Refactor interface for EMBL look and feel
- Extend image extraction retrospectively from 2006 using spot priced compute from AWS
- Provide weekly/monthly feed of patent structures to PubChem
- Add chemical structure tagging & search to full text content of Europe PMC
In the new year, we will run a webinar on SureChEMBL (which we will announce here), but in the mean-time we're very happy to take questions on the SureChEMBL support email address surechembl-help (at) ebi.ac.uk.
jpo