Research Code Distribution Across the Literature


Oh, I also stripped salt/batch codes (so GSK-123456A became GSK-123456). There are quite a few out of range values (too small, or unbelievably big) and then there are various ‘mutations’ that occur; either in writing the manuscript, or in typesetting, etc. Examples here are that there are 4 occurrences of GSK-112012 which is a small typo from the far more frequent (221 times) GSK-1120212, and it is easy to see how a simple transposition error could have caused this. To be clear, there will be a GSK-112012, it’s a valid name, but the likelihood is that references to this in the literature, without being supported by other evidence, are in fact about GSK-1120212. Interestingly, the occurrence rate of these mutants is about 10% of all unique GSK numbers (and this is a lower estimate - my first pass attempt at finding these relied on the first few digits being correct, edit-distance based clustering would be the place to start here of course). However, there do seem to be some more common transcription errors as one would expect for strings containing mostly numbers (so GSK-123456 -> GSK-12346 is a lot more likely to happen than becoming GSK-123q56). It’s likely to be the case that a set of 'real world' typos can readily be built to build modified ‘edit distances’ useful in cleaning up data. With such a high potential error rate, this could become critical in real-world use. Interestingly, these errors then propagate from paper to paper as they are copied from one source to another.

And here is a frequency scatterplot. Many compounds are mentioned only once in the literature. This dual-domain (1- order in time, not linear though! from ordinal number in the research code, and 2- frequency of mentions in the literature) ’frequency spectrum’ is really interesting and useful, as future posts will outline. There is also another time-domain at work here - the time of disclosure/publication.
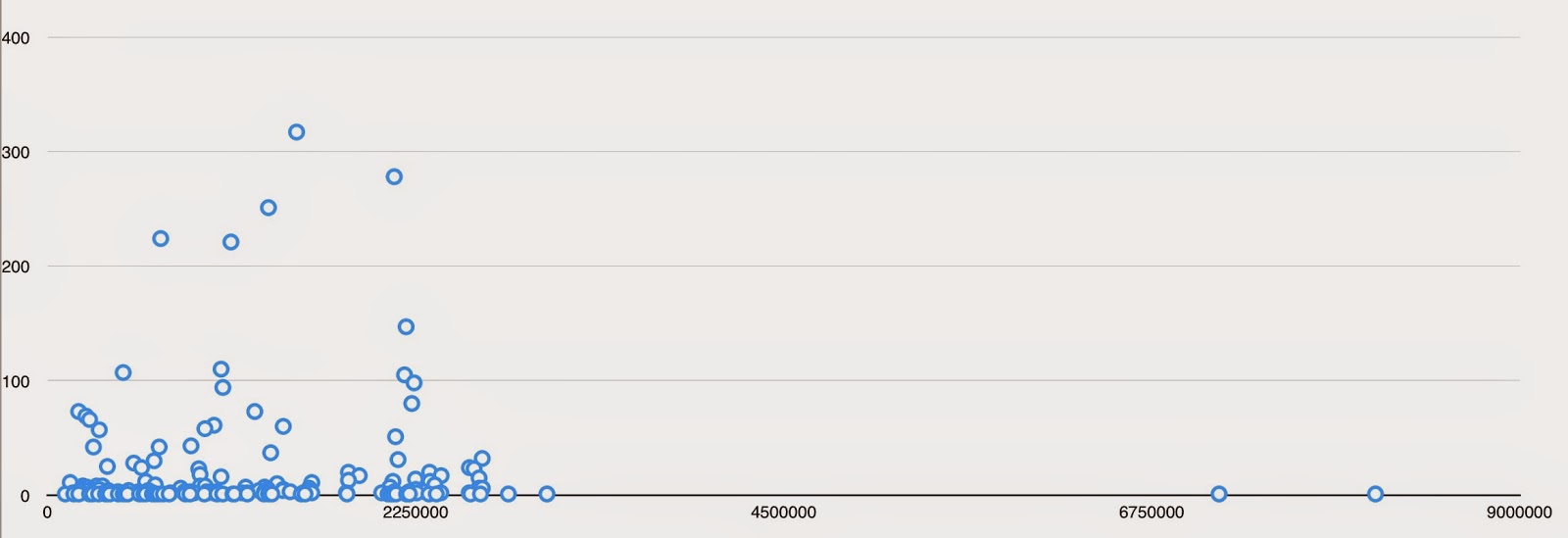
This initial analysis is just for EuropePMC full text content, but of course a similar analysis can be done across ChEMBL, SureChEMBL (for patents), the internet (in both search engine index, and with more complexity and difficulty across the dark-web). Of course, this can be combined with the list of research codes, and tracking across company mergers that is part of ChEMBL as well.
Toodle-pip for now!
jpo and Jee-Hyub Kim (McEntyre group)