The SureChEMBL map file is out

As many of you know, SureChEMBL taps into the wealth of knowledge hidden in the patent documents. More specifically, SureChEMBL extracts and indexes chemistry from the full-text patent corpus (EPO, WIPO and USPTO; JPO titles and abstracts only) by means of automated text- and image-mining, on a daily basis. We have recently hosted a webinar about it which turned out to be very popular - for those who missed it, the video and slides are here.
Besides the interface, SureChEMBL compound data can be accessed in various ways, such as UniChem and PubChem. The full compound dump is also available as a flat file download from our ftp server.
Since the release of the SureChEMBL interface last September, we have received numerous requests for a way to access compound and patent data in a batch way. Typical use-cases would include retrieving all compounds for a list of patent IDs, or vice versa, retrieving all patents where one or more compounds have been extracted from. As a result, we have now produced this so-called map file which connects SureChEMBL compounds and patents.
It is available here.
More information can be found in the README file.
What is this file?
There is a total of 216,892,266 rows in the map, indicating a compound extracted from a specific section of a specific patent document. The format of the file is quite simple: it contains compound information (SCHEMBL ID, SMILES, InChI Key, corpus frequency), patent information (patent ID and publication data), and finally location information, such as the field ID and frequency. The field ID indicates the specific section in the patent where the compound was extracted from (1:Description, 2:Claims, 3:Abstract, 4:Title, 5:Image, 6:MOL attachment). The frequency is the number of times the compound was found in a given section of a given patent. More information on the format of the file in the README file.
How many compounds and patents are there?
There are 187,958,584 unique patent-compound pairs, involving 14,076,090 unique compound IDs extracted from 3,585,233 EP, JP, WO and US patent documents - an average of ~52 compounds per patent. The patent coverage is from 1960 to 31-12-2014 inclusive.
Here's a breakdown of the patents in the map per year and patent authority:
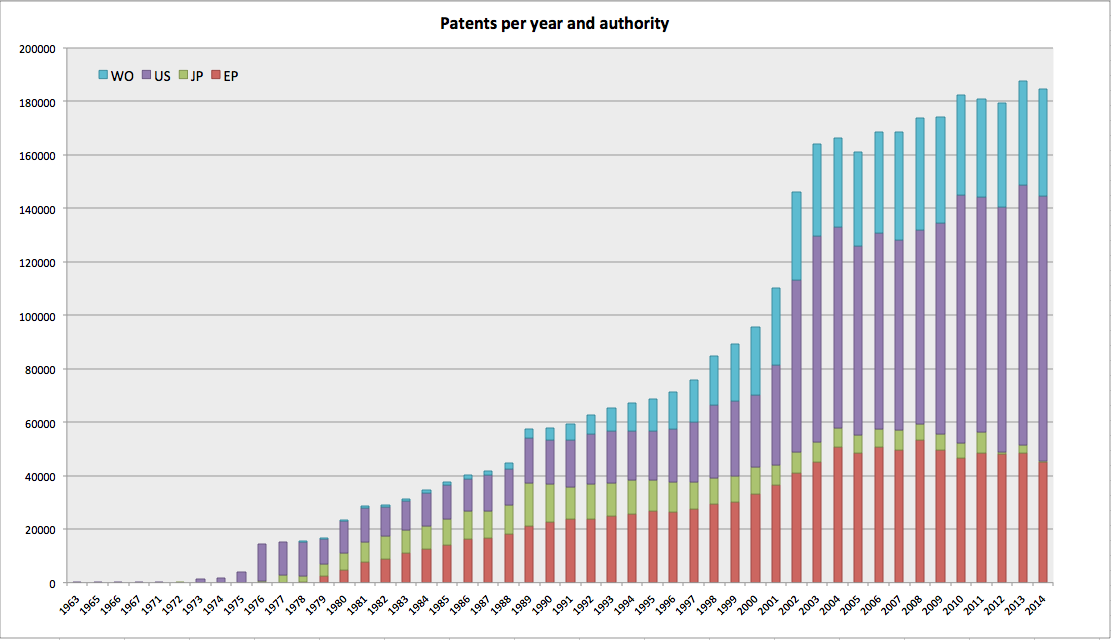
Here's a breakdown of the patents in the map per year and patent authority:
Are these all the compounds and patents in SureChEMBL?
Technically, no - in practice, yes. We excluded chemically annotated patents that are not immediately relevant to life sciences, such as this one. For the filtering, we used a list of relevant IPCR and related patent classification codes. At the same time, we excluded too small, too large, too trivial compounds, along with non-organic and radical/fragment compounds.
Are these compounds genuinely claimed as novel in their respective patents?
Automated methods to assess which are the important and relevant compounds in a pharmaceutical patent is a field of research and one of our future plans. For now, the map file include all extracted chemistry mentioned in all sections of a patent, subject to the filters listed in the previous section. A quick and effective trick to filter out trivial and/or uninformative compounds is to use the corpus frequency column and exclude everything with a value more than, say, 1000. Note that, in this way, you will also exclude drug compounds such as sildenafil, which are casually mentioned in a lot of patents. You could also look for compounds mentioned only in claims, description or images sections by filtering by the corresponding field ID.
What can I do with this?
Well, you can start by 'grepping' for one or more patent IDs or SCHEMBL IDs or InChI keys, followed by further filtering. Many of you will choose to normalise the flat file into 3 database tables (say compounds, documents and doc_to_compound) for centralised access and easy querying.
For example, to find the patents the drug palbociclib has been extracted from:
Any plans to update this map file?
New patents and chemistry arrive and are stored to SureChEMBL every day. We are planning to release new versions and incremental updates of the map file every quarter, in sync with the update of the compound dump files.
I couldn’t find my compound / patent - this compound should not be there
Don’t forget this an automated, live, high-throughput text-mining effort against an inherently noisy corpus such as patents. We are constantly working on improving data quality. If you find anything strange, let us know.
Can I join more metadata, such as patent assignee and title?
Obviously your first port of call would be the SureChEMBL website for patent metadata, but other services you may wish to use include the EPO web services for programmatic access.
Is there anything else?
Errr, yes. Watch this space for another post on storing and accessing live SureChEMBL data, behind your firewall.
The SureChEMBL Team
Is there anything else?
Errr, yes. Watch this space for another post on storing and accessing live SureChEMBL data, behind your firewall.
The SureChEMBL Team