-
UniChem: A resource for compound mapping - use in BioMedBridges
Unichem is a simple database and web service for the InChI-based linkage of chemical structures across various resources. It was initially developed under the EU-OPENSCREEN ESFRI as an approach to link screening data from the planned screening collection to other chemistry resources. The development was then extended under the BioMedBridges project - which spans across various Biomedical Sciences (BMS) ESFRIs (such as ELIXIR, BBMRI, etc.)
It's proved to be remarkably useful to us as well, and will be the future home of regularly updated feeds of compound structures from SureChEMBL - and will allow rapid novelty checking of patent structure novelty, across component datasources. A side-effect of this, is of course, that immediately the compounds in any of the BioMedBridge partner ESFRIs immediately have patent data integration. For us, this synergy, and snowball effect of binding resources together using simple open standards is one of the great joys of our work!
Follow @SureChEMBL for ongoing updates on status of the SureChEMBL resource. -
Notes from Rita's Talk Yesterday.
Rita gave a talk on her recent drug target work yesterday on campus, and Jenny Cham took notes; aren't they great?

jpo
-
SureChEMBL - Chemical Structure Information in Patents
Today we have announced that we are taking over the running of the SureChem system from Digital Science. We have renamed this SureChEMBL to reflect the history and provenance of the technology and engineering, but also to align it with it's new home and future, we like the name, and hope you do. We are delighted that this has happened - Nicko and the team at Digital Science have been great, and the more we have dug in to how it works, the more we have appreciated the design and vision that they had.
If there is one consistent piece of feedback we get about ChEMBL it is in encouraging us to add patent data to what we do. So now we have, but because the data from patents is different in detail from that reported in the published literature, we will keep the databases separate, but closely integrated.
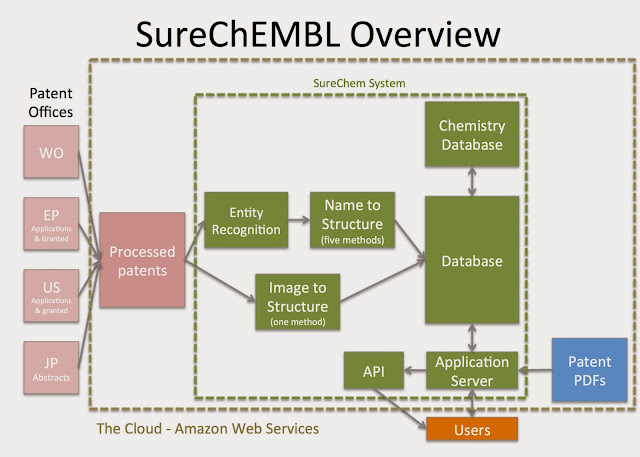
For those of you that are already SureChem users you will be familiar with the functionality and how it works; but for those that weren't SureChEMBL takes feeds of full text patents, identifies chemical objects from either the in-line text or from images and adds 2-D chemical structures. This is then loaded into a database and is searchable by chemical structure, so you can do substructure, similarity searching and so forth - all the good things you'd expect from a chemical database. This chemical search functionality is unavailable from the public, published patent documents, and is really essential for anyone seriously using the patent literature. Oh, and the system does this live, so as patents are published, they are processed and added to the system - the delay between publication and structures being available in SureChEMBL is about a day when converted from text, and a few days when converted from image sources.
SureChEMBL is hosted on the cloud - it's quite a complicated AWS solution, and it will take a few months for us to assume complete control of all the various parts, and, importantly keep things running smoothly behind the scenes, so the continuous access to fresh patent data is maintained.
SureChEMBL uses a number of third part software products in its operation, and arranging the licenses and permissions has been complex, and is still ongoing. The 3rd party software and data feeds used in SureChEMBL include:
Name to structure: ChemAxon, ACD/Labs, Perkin Elmer, OpenEye, OPSIN, NextMove
Chemical cartridge: ChemAxonImage to structure: Key ModulePatent data: FairView (IFI Claims) – processed patents, TwinDolphin – patent PDFs
These guys have all been a pleasure to work with so far, and SureChEMBL is a great showcase of their respective technologies and data:
We will host the system at the primary urls http://www.ebi.ac.uk/surechembl and also at http://www.surechembl.org - at the moment , these redirect to www.surechem.org, but as we switch things over they will point to servers provisioned by our team, so please start using these new urls for future access, although the original urls will continue to work into the future.
One of the more complicated things to transfer is the user accounts system - we can't simply transfer them over - and so have a plan to mail batches of users once a new sign-on system is in place in order to invite them to sign up to the new user account system. If you are not currently a registered user, please sign up with the current system, and we'll invite you to transfer over to our sign-on system once things are ready.
The EMBL-EBI has a broad range of life-science chemistry resources, and we integrate across chemistry related content using a chemical structure integration system call UniChem. In overview the EMBL-EBI chemistry resources include the following.
The future? - well the future is exciting, and we have lots of ideas to actively develop the SureChEMBL system. To be clear though, doing this will rely on us getting funding, and we're working hard on this. Some of the ideas we have for SureChEMBL include:
- Put SureChEMBL chemical content into UniChem
- Add sequence searching
- Add disease term, animal model, etc. indexing
- Development of community KNIME nodes
- Add links to/from Europe PMC
- Ligand Ensemble-based mapping of ChEMBL literature to patents
- Refactor interface for EMBL look and feel
- Extend image extraction retrospectively from 2006 using spot priced compute from AWS
- Provide weekly/monthly feed of patent structures to PubChem
- Add chemical structure tagging & search to full text content of Europe PMC
In the new year, we will run a webinar on SureChEMBL (which we will announce here), but in the mean-time we're very happy to take questions on the SureChEMBL support email address surechembl-help (at) ebi.ac.uk.
jpo -
Some Happy/Sad News
As regular followers of the ChEMBL-og or twitter will know, Ben Stauch had his viva voce and passed his thesis defence, and is now a fully fledged PhD graduate from the University of Cambridge. Ben hung around with us a little time after, working on a small fun project applying ChEMBL to compound/target selection. He is off fairly soon, so it's almost time to say goodbye and good luck to him. There's a few papers left from his predoc studies, so watch out for these as they appear.
He's now looking for jobs, and so if you are looking for someone who knows ChEMBL inside out, with a good background in NMR/X-ray, docking and simulation, stats and programming, he would be great employee! His LinkedIn profile is here if you want to get in touch with him.
'I am not a number, I am a free man', is not quite true for Ben, who is now actually a number - his ORCID is 0000-0001-7626-2021
It's also a pretty big milestone for me in my career - for over 20 years I worked in the commercial sector, so didn't supervise students, and Ben is the first I've helped get across the line. I really enjoy working with predocs - providing some coaching and support, encouraging independence, making introductions and assisting with networking, and most importantly in my view, trying to encourage a sense of wonder in discovery and knowing where the real challenges in the field are - avoiding the well-trod and over-explored paths. Our other students are also doing well - Felix has submitted, and Rita and Samuel are either writing up, or starting to write up. Oh, finally we have a new student, Jose, who will join us in January 2014.Enough of this sentimental self-reflection! This post is here to provide a link to Ben's thesis - this will eventually appear on the EMBL library site, but it's here, now.Good luck, thanks, and the very best of wishes the future Ben! -
A call for new MMV Malaria Box screening data depositions
 Last year, MMV released the MMV Malaria Box, a physical set of 400 probe- and drug-like compounds with confirmed anti-malarial activity. The 'Box' has been since distributed to a large number of academic labs around the world, where the compounds are screened against other plasmodia strains and pathogens such as schistosoma and mTB. The assay results have started coming back in the form of data depositions and, we, as MMV partners, are doing our best to integrate them with both the malaria-data database, as well as the main ChEMBL one. Recent examples of such MMV Malaria Box screening data depositions include:
Last year, MMV released the MMV Malaria Box, a physical set of 400 probe- and drug-like compounds with confirmed anti-malarial activity. The 'Box' has been since distributed to a large number of academic labs around the world, where the compounds are screened against other plasmodia strains and pathogens such as schistosoma and mTB. The assay results have started coming back in the form of data depositions and, we, as MMV partners, are doing our best to integrate them with both the malaria-data database, as well as the main ChEMBL one. Recent examples of such MMV Malaria Box screening data depositions include:
- An mTB screen by the Nathan lab in Cornell
- A schistosoma screen by Conor Caffrey and colleagues in UCSF
- A plasmodium apicoplast screen by the Derisi lab in UCSF, as reported in our post last week
In addition, we curate and integrate the bioactivity data produced by the excellent Open Source Malaria project.The value of sharing screening data openly, especially in the field of NTD basic research, could not be emphasised more,as it:- minimises the duplication of effort among labs
- accelerates research outcomes
- leads to more informed decisions
- fosters synergies and collaborations among researchers
- shifts the focus of competition to between ideas as opposed to data access rights
Therefore, we would like to encourage you to deposit your NTD/MMV box screening data, both positive AND negative, regardless of whether they have been published or not, to ChEMBL. We will make sure that your data are appropriately integrated, searchable and downloadable with their provenance visible and properly acknowledged. More importantly, we will make sure your data are open and freely shareable by everyone.
If you would like to deposit your data here or enquire further, please get in contact.The ChEMBL Team -
Paper: myChEMBL - a virtual machine implementation of open data and cheminformatic tools
We have just had a paper published in Bioinformatics on myChEMBL - the Linux VM that contains a fully functional version of the ChEMBL database. The paper is here.
myChEMBL is available for download at:
ftp://ftp.ebi.ac.uk/pub/databases/chembl/VM/myChEMBL/current
A warning, it is a fairly big download (ca. 18GB, so try and do this over a fast stable connection)
Source code is available here:
%T myChEMBL: A virtual machine implementation of open data andcheminformatics tools %J Bioinformatics %D 2013 %O DOI:10.1093/bioinformatics/btt666 %A M. Davies %A G. Papadatos %A F. Atkinson %A J.P. Overington
-
Job: Chemoinformatician at the Karolinska

Some of our collaborators at the Karolinska have a great job available - the advert is here.
DivisionChemical Biology Consortium Sweden (CBCS) are looking for a highly motivated and talented Cheminformatics Scientist to support and coordinate a wide scope of research informatics applications and data analysis at our Stockholm facilities.DutiesThe desired candidate will have a demonstrated track record in managing large volumes of scientific data in support of basic research and/or drug discovery projects and should have significant experience with in-house and commercial software solutions that facilitate data capture, analysis and visualization in small molecule research and drug design. Responsibilities include:- Evaluation and implementation of a nationally encompassing chemoinformatics system for the SciLifeLab community.
- Maintainance, configuration, monitoring, and/or troubleshooting scientific applications and underlying software.
- Partnering and interaction with software vendors and external professional service staff to resolve issues and implement enhancements.
- Assist scientists from multiple disciplines with data capture, analysis, visualization.
-
Competition Time - Teach-Discover-Treat 2014

Teach-Discover-Treat (TDT) is excited to announce our 2014 Competition. We have four exciting challenges that focus on developing and disseminating computational workflows for drug discovery of neglected diseases with a premium on reproducibility.
Three cash prizes - plus partial reimbursement of travel - will be awarded! Winners are required to present their work at the TDT Award symposium during the Fall 2014 ACS National Meeting in San Francisco, California.
Create and submit computational workflows that inspire drug discovery activities using freely available software tools. Detailed informationabout the 2014 Competition can be found here: http://www.TDTproject.org/2014-competition.html
Submissions deadline is February 3, 2014.
The TDT Steering Committee
Hanneke Jansen, Rommie Amaro, Jane Tseng, Wendy Cornell, Patrick Walters and Emilio Xavier Esposito
@TeachDiscoTreat