-
The incredible expanding universe of amino acids - Part 1
 There are 23 currently known, natural, genetically encoded amino acids - they are pictured above, ordered by the number of heavy atoms contained within them. There are the core 20, then the additional, more unusual ones selenocysteine, N-formyl-methionine and pyrrolysine - the latter two are used only in bacteria. Post-translationally, many further covalent modifications are found, for example phosphorylation of serine, threonine, tyrosine and histidine, but the above is the core building blocks of proteins, the incredible chemical diversity of the proteome can be through of as 'edits' on this core genetic set.
There are 23 currently known, natural, genetically encoded amino acids - they are pictured above, ordered by the number of heavy atoms contained within them. There are the core 20, then the additional, more unusual ones selenocysteine, N-formyl-methionine and pyrrolysine - the latter two are used only in bacteria. Post-translationally, many further covalent modifications are found, for example phosphorylation of serine, threonine, tyrosine and histidine, but the above is the core building blocks of proteins, the incredible chemical diversity of the proteome can be through of as 'edits' on this core genetic set.
All of the above are alpha amino acids, and all, with the exception of glycine have defined stereochemistry at the alpha carbon (they are all L-amino acids). Three of the amino acids have defined chirality in their side chains (isoleucine, threonine and pyrrolysine). There are only six elements used within this set (Carbon, Hydrogen, Nitrogen, Oxygen, Sulphur and Selenium). For me, to think that (along with some non-genetically encoded cofactors, such as ATP, Zinc, etc.) all the chemistry going on in our bodies comes from this simplicity is amazing. Of course, most of this complexity of function comes from the fact that the amino-acids can form polymers, so, although from the 20 'common' genetically encoded amino acids, there are 202 (400) possible dipeptides, 203 tripeptides, and so on; so the chemical space of peptides gets big, quickly - for a decapeptide there are over 10 trillion possible covalently distinct peptides (well more than that actually, if the presence of free thiol and connectivity isomers of disulphide bonds are considered). This diversity of peptides has been well explored, but we became interested some time ago in identifying other useful amino acids.
You can go a long way with this set of building blocks, however, sometimes it is desirable to include other amino acids into drugs or proteins, for example the drug Desmopressin, a vasopressin receptor agonist has a deaminated N-terminus and the unnatural chiral form of Arginine (D-Arginine) at the eighth position - these improve drug properties compared to dosing with the natural peptide. Occasionally, more radically different amino acids are used (e.g. Aib, alpha-aminoisobutyric acid at position 2 of the clinical candidate Taspoglutide (a GLP-1 mimetic)). -
Citing ChEMBL, and Data DOIs
There are now multiple formats and ways to access the ChEMBL data, and we have recently assigned DOIs to all available versions of ChEMBL (and will archive these on the ftp server, permanently).So when you publish use of ChEMBL, could you reference the following papers:ChEMBL DatabaseA. Gaulton, L. Bellis, J. Chambers, M. Davies, A. Hersey, Y. Light, S. McGlinchey, R. Akhtar, A.P. Bento, B. Al-Lazikani, D. Michalovich, & J.P. Overington (2012) ‘ChEMBL: A Large-scale Bioactivity Database For Chemical Biology and Drug Discovery’ Nucleic Acids Res. Database Issue, 40 D1100-1107. DOI:10.1093/nar/gkr777 PMID:21948594A.P. Bento, A. Gaulton, A. Hersey, L.J. Bellis, J. Chambers, M. Davies, F.A. Krüger, Y. Light, L. Mak, S. McGlinchey, M. Nowotka, G. Papadatos, R. Santos & J.P. Overington (2014) ‘The ChEMBL bioactivity database: an update’ Nucleic Acids Res. Database Issue, 42 1083-1090. DOI:10.1093/nar/gkt103 PMID: 24214965myChEMBLR. Ochoa, M. Davies, G. Papadatos, F. Atkinson and J.P. Overington (2014) 'myChEMBL: A virtual machine implementation of open data and cheminformatics tools' Bioinformatics. 30 298-300. DOI10.1093/bioinformatics/btt666 PMID: 24262214ChEMBL RDFS. Jupp, J. Malone, J. Bolleman, M. Brandizi, M. Davies, L. Garcia, A. Gaulton, S. Gehant, C. Laibe, N. Redaschi, S.M Wimalaratne, M. Martin, N. Le Novère, H. Parkinson, E. Birney and A.M Jenkinson (2014) 'The EBI RDF Platform: Linked Open Data for the Life Sciences' Bioinformatics 30 1338-1339 DOI:10.1093/bioinformatics/btt765 PMID:24413672Also please reference the version of ChEMBL you may have used in any published analyses, using the following DOIs:DatasetDOIChEMBLCHEMBL0110.6019/CHEMBL.database.01CHEMBL0210.6019/CHEMBL.database.02CHEMBL0310.6019/CHEMBL.database.03CHEMBL0410.6019/CHEMBL.database.04CHEMBL0510.6019/CHEMBL.database.05CHEMBL0610.6019/CHEMBL.database.06CHEMBL0710.6019/CHEMBL.database.07CHEMBL0810.6019/CHEMBL.database.08CHEMBL0910.6019/CHEMBL.database.09CHEMBL1010.6019/CHEMBL.database.10CHEMBL1110.6019/CHEMBL.database.11CHEMBL1210.6019/CHEMBL.database.12CHEMBL1310.6019/CHEMBL.database.13CHEMBL1410.6019/CHEMBL.database.14CHEMBL1510.6019/CHEMBL.database.15CHEMBL1610.6019/CHEMBL.database.16CHEMBL1710.6019/CHEMBL.database.17CHEMBL1810.6019/CHEMBL.database.18CHEMBL1910.6019/CHEMBL.database.19ChEMBL-RDFChEMBL-RDF/16.010.6019/CHEMBL.RDF.16.0ChEMBL-RDF/17.010.6019/CHEMBL.RDF.17.0ChEMBL-RDF/18.010.6019/CHEMBL.RDF.18.0ChEMBL-RDF/18.110.6019/CHEMBL.RDF.19.0myChEMBLmyChEMBL-17_010.6019/CHEMBL.myCHEMBL.17.0myChEMBL-18_010.6019/CHEMBL.myCHEMBL.18.0Future releases will adhere to the following patterns. We will be modifying the attribution part of the ChEMBL license to require reporting of these DOIs in publications that use ChEMBL. We hope this will contribute to reproducibility of analyses. -
Registry numbers in ChEMBL
The numbers are in - the public vote (N=69, so quite small) was overwhelmingly (in roughly a 3:1 ratio) in favour of including registry numbers in ChEMBL/UniChem, as you will see from the screenshot above. There was some discussion (see Google+ and ChEMBL-og comments for details, as well as some Twitter response (it's pretty easy to hunt down if you are really really interested). So we will see what we can do..... -
ChEMBL US Tour - an update
We've had a great response to our call for offers of venues to help us on a ChEMBL outreach tour, funded by the SMSDrug.net project. Things are shaping up pretty well, but we probably still have space for something in the Seattle area, and also space maybe for something in Philadelphia. We also will probably do both East and West coasts on the same trip, due to the very positive response.Get in touch if you are in the north-west, or north-east!jpo -
ChEMBL US Tour 2014
We have some specific funding to do some training and outreach for ChEMBL (including UniChem and SureChEMBL). We would like to set something up on either the East or West coasts - the map above is the Google Analytics view for the blog (remember, we don’t run any analytics on the ChEMBL site, we respect your privacy). Based on this there are a couple of realistic options, and we can realistically only do one of these this year.- West Coast - Seattle, Bay Area and San Diego. or
- East Coast - RTP, DC, Philly, New York, New Jersey and Boston.
We are thinking of sometime in November or early December 2014.In order to make this work, we would need a local coordinator to arrange rooms, advertising to local interested users, and so forth, and also some assistance with logistics planning, and if you have access to special rates at hotels that would be great.We could run either a lecture/chalk-and-talk set of lectures at each location, or if you have a training room with computers could do some workshops/hands-on training. We would typically cover- Introduction to ChEMBL, UniChem and SureChEMBL
- Application of ChEMBL in lead discovery and medicinal chemistry
- patent searching in SureChEMBL
- Drugs and Targets in ChEMBL
- Using KNIME with ChEMBL
- Database schema and SQL querying, myChEMBL.
So, any interest in hosting us for a day, and what would you like to hear about? Please mail us!If there is sufficient interest, we will look into which option (East or West coast) has the most potential meetings.
Once we’ve set something up, we’ll post an itinerary an further details on the ChEMBL-og. -
Should CAS numbers be in ChEMBL and/or UniChem?

A very quick survey to add excitement to either your holiday or work-day! None of these sucker links, where there appears a 0.24% complete progress bar on the second page, it's just a simple yes/no question on whether it's a good idea to add CAS registry numbers to ChEMBL and/or UniChem. No promises that we could deliver this, but depending on what you vote for, we will consider our options.
Update: Given the multiple channels out there, there are also comments on this on LinkedIn (in the ChUG - "ChEMBL User Group" group - why not join, if you're not already) and a couple on Google+.
Update 2: I'll let the poll run till the end of the week (Friday 8th 2014) - and then write something up on the results. -
ChEMBL_19 Released - Now with Crop Protection Data!
 We are pleased to announce the release of ChEMBL_19. This version of the database was prepared on 3rd July 2014 and contains:
We are pleased to announce the release of ChEMBL_19. This version of the database was prepared on 3rd July 2014 and contains:
- 1,637,862 compound records
- 1,411,786 compounds (of which 1,404,752 have molfiles)
- 12,843,338 bioactivities
- 1,106,285 bioassays
- 10,579 targets
- 57,156 abstracted documents
New crop protection data
We have now expanded the content of ChEMBL to include data relevant to crop protection research. Bioactivity data covering insecticides, fungicides and herbicides were extracted from a number of different journals such as J. Agric. Food. Chem., J. Pesticide Sci., Crop Protection and Pest Manag. Sci. The addition of this dataset to ChEMBL was funded by Syngenta. In total, more than 40K compound records and 245K activities were added in this dataset. These data are included in the 'Scientific Literature' data source and can be retrieved from the ChEMBL interface using the taxonomy browser ('Browse Targets' -> 'Taxonomy') or through assay keyword searches (e.g., 'insecticidal', 'herbicidal').

Other changes since the last release
New neglected disease data sets
ChEMBL_19 includes the following data sets:
- MMV malaria box Plasmodium falciparum screening data deposited by Eisai
- MMV malaria box Onchocerca lienalis screening data deposited by Northwick Park Institute for Medical Research
- MMV malaria box Cryptosporidium parvum screening data deposited by the University of Vermont
- Trypanosoma cruzi fenarimol series screening data deposited by Drugs for Neglected Diseases Initiative (DNDi)
- Plasmodium falciparum screening data from the Open Source Malaria project.
Hepatotoxicity data
Hepatotoxicity information for more than 1,200 compounds has been extracted from the following publication, relating to the 14th edition of the Drug hepatotoxicity bibliographic database:
- Biour M, Ben Salem C, Chazouillères O, Grangé JD, Serfaty L and Poupon R. [Drug-induced liver injury; fourteenth updated edition of the bibliographic database of liver injuries and related drugs]. Gastroenterol. Clin. Biol., 2004, 28(8-9), 720-759.
New journal coverage
We are now pleased to be able to include MedChemComm in our list of journals for routine data extraction. ChEMBL_19 includes 120 articles from this excellent journal, published between 2013 and 2014. We are most grateful to the RSC for access to the source journal material. We will post more on this exciting new partnership in a future blog post!
Interface enhancements
New compound sketcher:
The ligand search now provides ChemAxon's Marvin JS sketcher as default for substructure/similarity searches.
Cochrane Collaboration reviews and British National Formulary (BNF) entries:
For drugs, the compound report card now provides links to any available Cochrane reviews and entries in the British National Formulary.
 UniChem cross references:
UniChem cross references:
UniChem now contains two additional sources: NMRShiftDB and the LINCS program. Cross references to these databases (where the compound occurs in the relevant source) are now provided on compound report card pages.
As usual, contact us at chembl-help@ebi.ac.uk for any questions/feedback.
The ChEMBL Team -
Research Code Distribution Across the Literature
As you will see from many previous blog posts, we like compound research codes (alternatively known as company codes). These are often the first and primal identifier for a compound in the literatures, and reports of activity often pre-date disclosure of structure. They are of key importance in having view of state-of-the-art for progress against a target, etc, and are often the only way to search for bioactivity across a broad set of literature sources. They also have many other applications, such as competitive intelligence, investor/analyst data mining, etc.
Above is a plot of the frequency of occurrence in full text of 808,378 Open Access EuropePMC articles for GSK codes across EuropePMC - I’ve canonicalised them to account for differences in punctuation (“GSK-123456”, “GSK123456” and “GSK 123456”). If you do a google search for the most common ones, you will easily see the importance of these compounds across drug discovery and pharmacology. For example GSK-1521498 is a mu opioid receptor antagonist, with (as of today) 158,000 hits in google).
I chose GSK codes for a few reasons 1) because they are a large, ethical research company, with a commitment to publication of research 2) that they are local to us here in Hinxton, and it’s easy to ask questions of our local friends 3) GSK don’t switch early company codes to development stage codes, or use a duality of names, which complicate simple analysis - a nice example here is for the recently approved kinase inhibitor Alectinib, which goes under the following codes: RG-7853, CH-5424802, AF-802 and Ro-5424802. In fact there are some complexities - for example in the GSK pipeline web-page, they don't themselves use the GSK prefix, just integers; but here, in this context, it is implicit they will be GSK codes.
Oh, I also stripped salt/batch codes (so GSK-123456A became GSK-123456). There are quite a few out of range values (too small, or unbelievably big) and then there are various ‘mutations’ that occur; either in writing the manuscript, or in typesetting, etc. Examples here are that there are 4 occurrences of GSK-112012 which is a small typo from the far more frequent (221 times) GSK-1120212, and it is easy to see how a simple transposition error could have caused this. To be clear, there will be a GSK-112012, it’s a valid name, but the likelihood is that references to this in the literature, without being supported by other evidence, are in fact about GSK-1120212. Interestingly, the occurrence rate of these mutants is about 10% of all unique GSK numbers (and this is a lower estimate - my first pass attempt at finding these relied on the first few digits being correct, edit-distance based clustering would be the place to start here of course). However, there do seem to be some more common transcription errors as one would expect for strings containing mostly numbers (so GSK-123456 -> GSK-12346 is a lot more likely to happen than becoming GSK-123q56). It’s likely to be the case that a set of 'real world' typos can readily be built to build modified ‘edit distances’ useful in cleaning up data. With such a high potential error rate, this could become critical in real-world use. Interestingly, these errors then propagate from paper to paper as they are copied from one source to another.
Below is the frequency distribution of each cleaned up GSK- code, it shows the classic log-normal/power law distribution - with some compounds, very likely the most interesting, with most data. They are also likely to be the most progressed towards becoming a real drug. The long tail is there too, and one would expect that this long tail is more likely to be full of errors than the commonly referred to compounds.
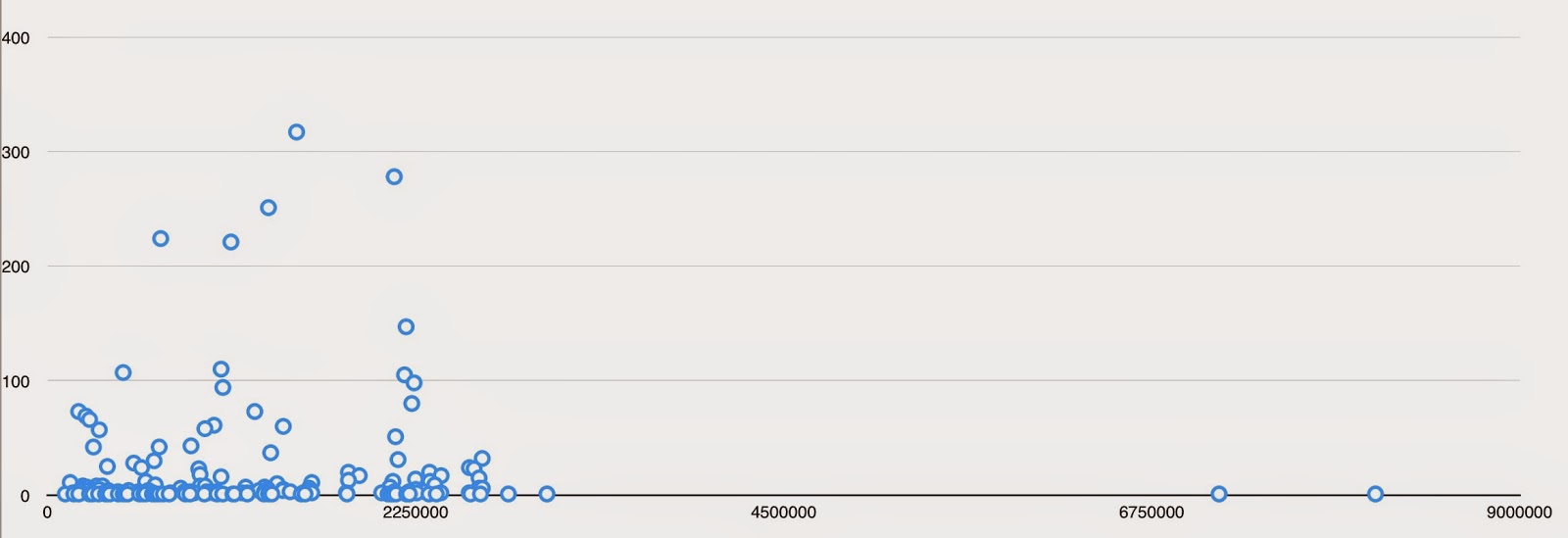
And here is a frequency scatterplot. Many compounds are mentioned only once in the literature. This dual-domain (1- order in time, not linear though! from ordinal number in the research code, and 2- frequency of mentions in the literature) ’frequency spectrum’ is really interesting and useful, as future posts will outline. There is also another time-domain at work here - the time of disclosure/publication.
This initial analysis is just for EuropePMC full text content, but of course a similar analysis can be done across ChEMBL, SureChEMBL (for patents), the internet (in both search engine index, and with more complexity and difficulty across the dark-web). Of course, this can be combined with the list of research codes, and tracking across company mergers that is part of ChEMBL as well.
Toodle-pip for now!
jpo and Jee-Hyub Kim (McEntyre group)